|
Recently, a lot of conversation has been circulating regarding what constitutes a microbe. How do we know we captured the diversity in a system and have a representative sample or sequence? Are abundant, relevant members of a community culturable? If not, how can we be sure that the computational output is representative? Especially with the increased use of culture-independent methods in microbiome research, we are relying heavily on the molecular and computational methods to assess this vast diversity of microorganisms. For this post, I will focus less on ideas of microdiversity (although this will come briefly later) within 16S defined OTU/ESVs. Instead, I want to highlight some of the more interesting conversations happening in microbial ecology regarding 1) culturability and 2) metagenome-assembled genomes or MAGs. This post largely spawned from the amazing dialogue being generated over Twitter over these two issues, and I just wanted to give my opinion on the topics. I will refrain from "taking sides" but focus on the arguments and the bigger picture implications for microbiome research. High proportions of bacteria are culturable across major biomesLet's start here because I think this is a SUPER important topic and obviously will relate to the second conversation below. For decades, microbiologists have leaned heavily on a major crutch: paradigm that only 1% of microorganisms are culturable A recent communication by Adam Martiny in ISME [1] challenged this paradigm in microbiology by arguing that, based on 16S rRNA similarity of bacteria, abundant members (35-52% of sequences and taxa, respectively) across major biomes have a representative member in a cultured isolate. At first, I was delighted to see this communication published. Just weeks before this, I saw multiple seminars and job talks starting the Introduction with highlighting this paradigm. Inevitably, it came across, that "well we can't culture bacteria, so why even try?". Subsequently, the talks would go over culture-independent approaches to navigate this "massive hurdle" in microbiology. But this is a major disservice to all the hardwork done to culture bacteria. Everything, in theory, is culturable - it's a matter of figuring out how to do it. The question shouldn't be is X bacterium culturable? it should be how do we culture it? This ideology of yet-to-be cultured microbes is definitely painstaking work, but it is possible (everyone please check out the incredible work of Yoichi Kamagata to characterize anaerobic bacteria and their syntrophic relationships - some culturing issues were resolved just by switching the preparation of the media! [2]).
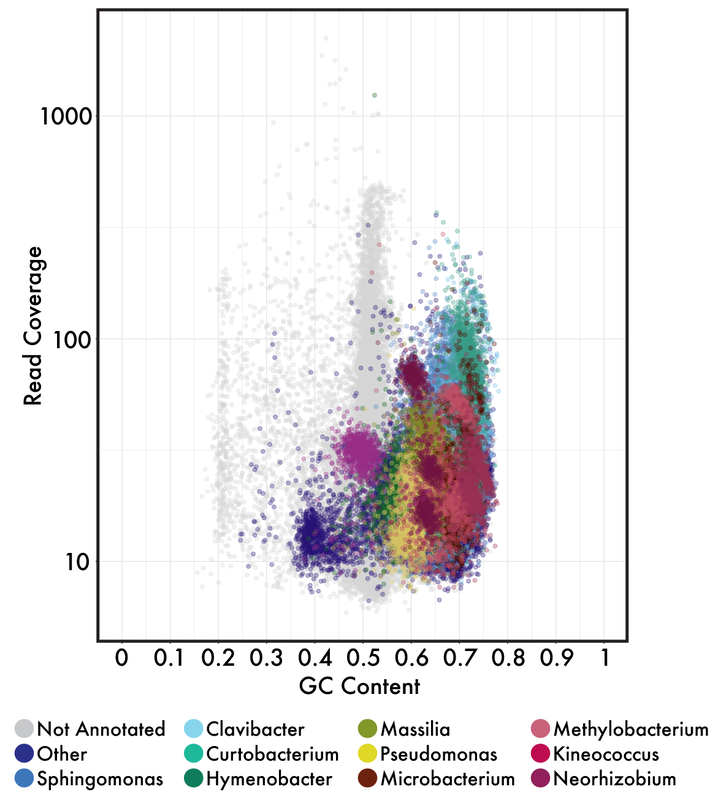
Both of these papers make great points and address topics that every microbiologists should be thinking about. As I have said before, many studies infer far too much from descriptive datasets of 16S rRNA community analyses. It is almost impossible to relate this data or the observed taxa to ecological function. I have spent a lot of time laying out some of these arguments, but basically comes down to the 16S rRNA gene provides a coarse depiction of the microbial community. There are millions of years of divergence and adaptation masked by the use of conserved marker genes. These are some of the similar points the Steen et al. paper lay out to argue against the idea that most organisms have been cultured. However, I do feel like this resolution, specifically with 16S rRNA studies, it is relevant to compare against databases. This is exactly what Martiny's response [4] details that the most common interpretation using a defined taxonomic unit (OTU) implies a lot of abundant members have cultured representatives in databases, certainly superseding the 1% "rule". In any case, how you define whether a taxa is cultured or what is the real number so far really depends on interpretation. And based on this interpretation, researchers need to apply appropriate methods. If you are concerned with fine-scale diversity, do not use 16S rRNA surveys. If you want to target a specific group, design taxa-specific primers. If you want to infer function and avoid PCR and molecular biases, probably switch to metagenomes. And finally, if you wish to link genotype to phenotype, figure out a way to culture and target the abundant members of your system. Physiological data can provide a lot and was the basis for most of my work to target isolates. Artificial construction of metagenome assembled genomes (MAGs)???I think this is a nice segue into the next topic. Based on the vastly different ways to interpret culturability of a microbe, I think it is super interesting that MAGs aren't more of a topic of discussion. For those who are unfamiliar, MAGs are extracted from metagenomic data using computational approaches to assemble "community" data, bin assembled contigs into similar sequences based on genomic signatures (e.g., %GC, tetranucleotide frequencies), and assess contamination to create MAGs of otherwise yet-to-be-cultured ;) bacteria or archaea (schematic below).
As many members were quick to point out, cultured isolates exist for the novel lineages where high quality MAGs (i.e., complete genomes) match pretty nicely. As an ultra bonus, one of the "artificial" lineages detailed in the preprint recently was isolated and described in another preprint documenting a 12 year(!) isolation effort for Asgard Archaea - this is why science is so awesome! Further, a really talented grad student in the Banfield Lab, Alex Crits-Christoph, re-analyzed this data to address the main support against MAGs in the preprint: The effect observed is due to differences in the phylogenetic distribution of genomes from metagenomes vs isolate genomes.
I personally think the authors vastly overstate their conclusions but I do think they bring up a few good points, especially if we start to bring in the ideas from the previous section. MAGs are useful because we can essentially sequence the entire microbial community and "pull out" genomes without isolating strains. This was incredibly useful in simple microbial communities where low genetic diversity allowed for the relatively easy binning of MAGs. However, I do start to question how much of MAGs, especially in complex, genetically-diverse systems, are a representation of a mosaic of closely-related strains and/or lineages.
Papers:1. Martiny AC. (2019). High proportions of bacteria are culturable across major biomes. ISME 13: 2125-2128.
2. Kato S, Yamagishi A, Daimon S, Kawasaki K, Tamaki H, Kitagawa W, Abe A, Tanaka M, Sone T, Asano K, Kamagata Y. (2018). Isolation of Previously Uncultured Slow-Growing Bacteria by Using a Simple Modification in the Preparation of Agar Media. Applied Environmental Microbiology 84: e00807–18. 3. Steen AD, Crits-Christoph A, Carini P, DeAngelis KM, Fierer N, Lloyd KG, Thrash JC. (2019). High proportions of bacteria and archaea across most biomes remain uncultured. ISME. 4. Martiny AC. (2019). The '1% culturability paradigm' needs to be carefully defined. ISME. 5. Garg SG, Kapust N, Lin W, Tria FDK, Nelson-Sathi S, Gould SB, Fan L, Zhu R, Zhang C, Martin WF. (2019). Anomalous phylogenetic behavior of ribosomal proteins in metagenome assembled genomes. bioRxiv. 6. Chase AB, Karaoz U, Brodie EL, Gomez-Lunar Z, Martiny AC, Martiny JBHM. (2017). Microdiversity of an abundant terrestrial bacterium encompasses extensive variation in ecologically relevant traits. mBio 8: e01809-17.
1 Comment
Natural ProductsAbout 9 months ago, I started my postdoc in a brand new field, natural products. Instead of focusing on the processes contributing to microbial diversity and diversification, the objective is to utilize microbes for the discovery of new natural products. As a total novice, I was blown away by the amazing work being done to quantify single microbial compounds. So, as I look back on what I learned over the past few months, I just wanted to highlight some of the amazing and novel techniques being used to give us insights into the structural diversity and complexity of natural products. This is my (very) humble understanding of natural products and definitely going to be a bit biased towards Scripps and marine sediment bacterium!
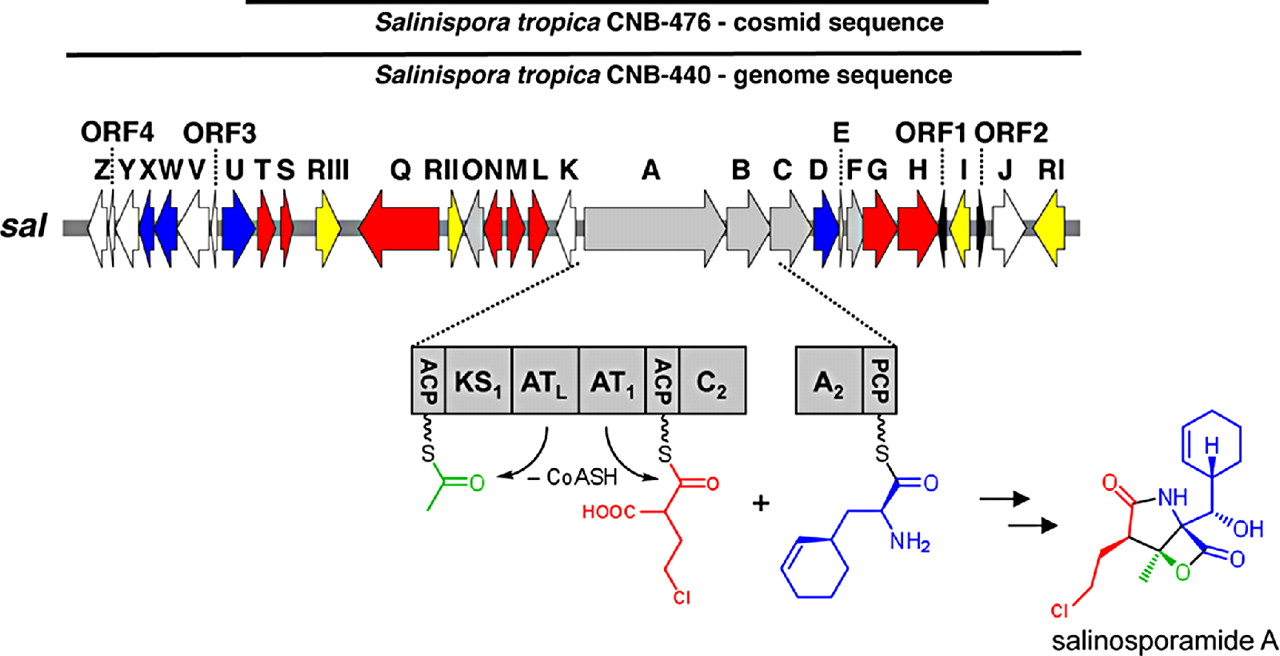
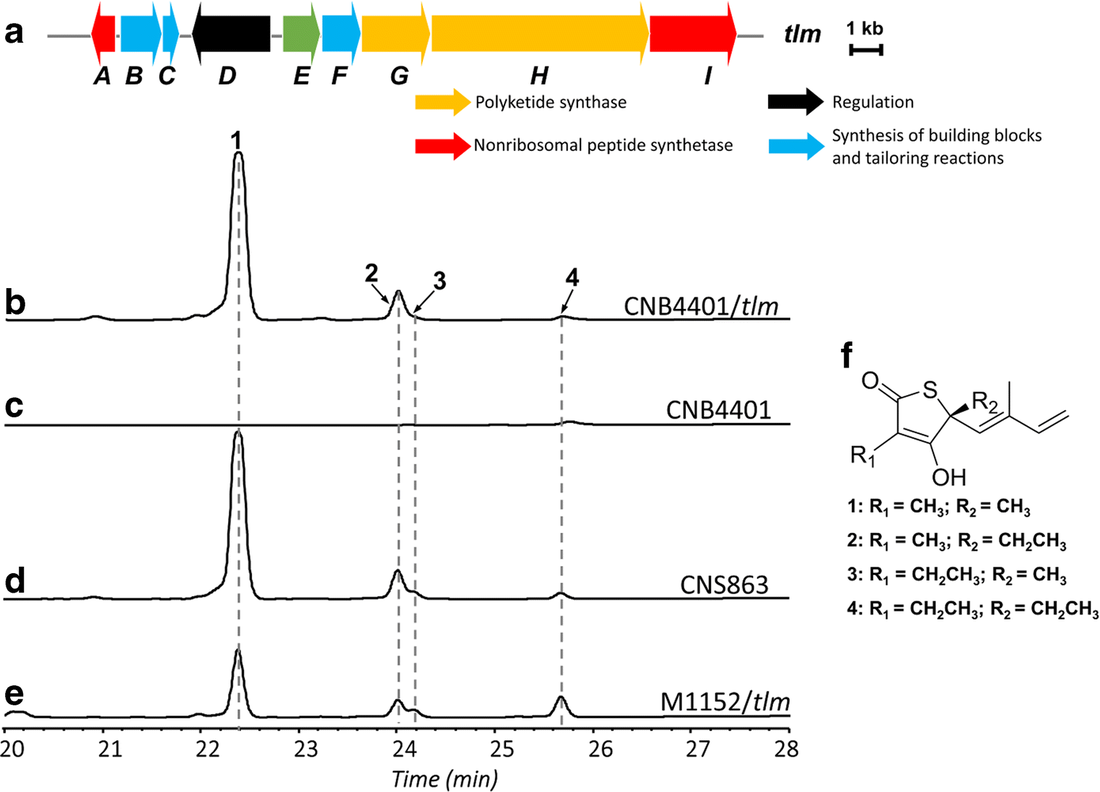
Genome Mining for NPsOf course I would start here! Obviously, the major advances in sequencing technology and costs have allowed for extensive mining of genomes for genetic signatures related to the production of natural products. In bacteria, these genes are typically clustered in the genome to build proteins in a modular fashion (akin to a car assembly line). Modules within these biosynthetic gene clusters (BGCs) enable the loading, attachment, and extension of building blocks to produce NPs (below Figure).
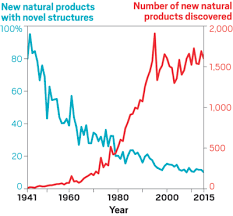
Decades of work identifying novel genomic signatures for BGCs has allowed for extensive surveys across bacterial taxa. Most notably are the Actinobacteria, which include the well-studied NP producing genera such as Streptomyces and Salinispora. Genome mining has revealed large portions of the genome can be dedicated to the production of NPs. This computational approach assesses the entire biosynthetic potential of an organism rather than examining individual metabolites (of which may or may not be expressed in culture conditions due to regulation or environmental signaling). Mass SpectrometryTraditionally, strains are grown in culture and crude extracts are examined to determine which products a bacteria might be producing. This led to the one strain many compounds (OSMAC) approach to characterize diverse compounds in different culture conditions (see below figure). However, analyzing these crude extracts are difficult as secondary metabolites are highly diverse in their size, structure, and physicochemical properties. Instruments such as the LC-MS (liquid chromatography - mass spectrometry) can separate and identify masses of compounds, but still an organisms can produce hundreds of compounds in any given sample. Much work is still to be done, but analytical tools, such as GNPS and MZMine, can aid with the data processing and identification (and dereplication) to characterize compounds. 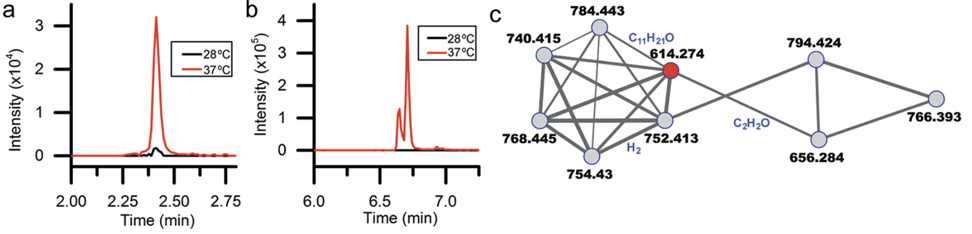 Identification of molecules A) 614.27 m/z and B) 754.44 m/z in high temperature culturing conditions. C) Molecular networking based on MS2 spectra (via GNPS) clustered both masses with a known natural product (red node) [3]. Heterologous Expression of BGCsLinking the identification of BGCs to their products using mass spec is really difficult. As such, most of the "low-hanging fruit" have been characterized in most model organisms for natural products research. This has led to some creative approaches to identify novel secondary metabolites. With the advances in computational tools, exploring biosynthetic potential in the genome has revealed a number of "orphan" BGCs in genomes, or identified BGCs that have yet to be linked to its corresponding molecule.
Papers:1. Pye CR, Bertin MJ, Lokey RS, Gerwick WH, Linington RG. (2017). Retrospective analysis of natural products provides insights for future discovery trends. Proceedings to the National Academy of Sciences 114(22): 5601-5606.
2. Eustáquio AS, McGlinchey RP, Liu Y, Hazzard C, Beer LL, Florova G, Alhamadsheh MM, Lechner A, Kale AJ, Kobayashi Y, Reynolds KA, Moore BS. (2009). Biosynthesis of the salinosporamide A polyketide synthase substrate chloroethylmalonyl-coenzyme A from S-adenosyl-l-methionine. Proceedings to the National Academy of Sciences 106(30): 12295-12300. 3. Sidebottom AM, Johnson AR, Karty JA, Trader DJ, Carlson EE. (2013). Integrated metabolomics approach facilitates discovery of an unpredicted natural product suite from Streptomyces coelicolor M145. ACS Chemical Biology 8: 2009-2016. 4. Zhang JJ, Moore BS, Tang X. (2018). Engineering Salinispora tropica for heterologous expression of natural product biosynthetic gene clusters. Applied Microbiology and Biotechnology 102(19): 8437-8446.
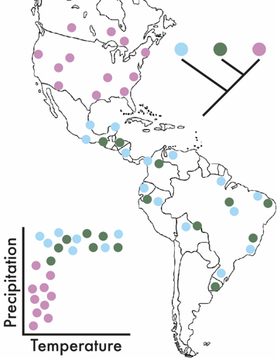
This is where adapting a biogeographic framework can be powerful. It allows us to assess the processes controlling the geographic distribution of species over space and time. It can incorporate ecological and environmental factors (e.g., temperature and precipitation) while also allowing for the integration of phylogeography to assess evolutionary processes (Figure). These ideas have a rich history in plant and animal communities and have lead to the develop of ground-breaking ecological theories attempting to explain species diversity and distribution (for some ecological background, see MacArthur-Wilson, Hubbell's Neutral Theory, and/or a nice synthesis by M Vellend). In the past two decades, these patterns have largely been explored in microbial communities, reflecting the importance of selection of environmental conditions based on correlations between microbial composition and the environment. For instance, one of the first papers to really explore these patterns showed soil bacterial communities were highly influenced by pH [1]. However, there is a large disconnect between theoretical and empirical work conducted in plants and animals to microbes, as the former are studied at the species level and describe large-scale patterns of species’ distributions. By concentrating on finer-genetic resolutions (i.e., species and population levels) we can better detect the eco/evo processes contributing to the maintenance of microbial diversity [2]. Deterministic or Stochastic?!?!For this section, I just want to highlight some processes that have been shown (in either bacteria or macroorganisms) to maintain species diversity. For the ease of this blog post, I will broadly separate these into two major categories, deterministic and stochastic processes. This, in no way comprehensive list is mainly derived from the amazing ecology grad course taught by my PhD advisor, Jennifer Martiny at UC Irvine.
This is where I think microbial ecologists can vastly expand our understanding of the tremendous microbial diversity. For instance, niche partitioning requires relating traits to phylogeny which should reflect differential environmental distributions. Often, this requires quantifying traits of closely-related bacteria as the competitive exclusion principle predicts a limitation to niche differences. Furthermore, huge efforts are being made to quantify the relative impacts of deterministic v. stochastic processes in microbial studies, both from theoretical frameworks [3] to experimental [4]. Papers:1. Fierer N & Jackson RB. (2006). The diversity and biogeography of soil bacterial communities. Proceedings to the National Academy of Sciences 103(3): 626-631.
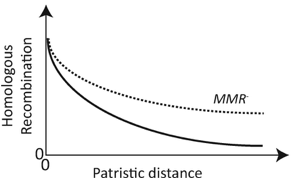
2. Chase AB & Martiny JBH. (2018). The importance of resolving biogeographic patterns of microbial microdiversity. Microbiology Australia 39(1): 5-8. 3. Ning D, Deng Y, Tiedje JM, Zhou J. (2019). A general framework for quantitatively assessing ecological stochasticity. Proceedings to the National Academy of Sciences 116(34): 16892-16898. 4. Albright MBN, Chase AB, Martiny JBH. (2019). Experimental evidence that stochasticity contributes to bacterial composition and functioning in a decomposer community. mBio 10:e00568-19. Theme of the month: horizontal gene transferHGT has the power to accelerate evolution by introducing novel alleles across phylogenetically distant taxa. At the same time, rampant HGT can blur species boundaries and is expected to result in a mosaic of genes. I have always been fascinated by the idea that bacteria undergo rampant HGT insomuch that there have been previous proposals for a "web of life". As much as HGT can contribute to rapid diversification, there is also strong evidence for cohesive bacterial lineages, which is fundamental to our understanding of biodiversity in the microbial kingdom. These ideas seem to create an evolutionary "tug-of-war" between local adaptation mediated via acquisition of beneficial alleles and shared phylogenetic history. Here, I just wanted to highlight some new(ish), excellent papers addressing the idea of HGT across multiple scales, from theoretical to empirical, and HGT across kingdoms. Brief Introduction: HGT vs. recombination
At the same time, there are interesting patterns when looking at closely-related bacteria. For one, when comparing genomes of closely-related bacteria, many of the genes in the genomes are unique, or not found in all strains. These genes are collectively referred to the pan-genome. Repeatedly, studies find almost infinite pan-genomes when surveying bacterial groups. Whether these genes are neutral or are a result of frequent adaptive HGT in local environments remains up for debate. Some have proposed that local populations can tap into a shared gene pool as many of these accessory or flexible genes are under frequency-dependent selection [2]. This would suggest that flexible genes are under strong environmental selective pressures. While HGT can possibly provide beneficial fitness effects, there must be a cost to acquiring foreign DNA. Simply put, for adaptive genes to be maintained in a population, the beneficial effects must far out-weigh detrimental effects or genetic drift [3]. This is why HGT fascinates me. There is an intrinsic cost to accepting foreign DNA, but we know HGT can drastically shape microbial evolution. Personally, I believe many studies have overestimated HGT events or are documenting "evolutionary relic" events, such as using gene homology to overestimate the extent of HGT in bacterial genomes. This is why, I suggest when reading the following list to keep in mind some questions: 1. How prevalent is HGT in natural systems? Obviously we can induce genetic exchange in the laboratory or under high selective pressures, but how common are these events in nature? 2. Is HGT a hand-wavy explanation for unexplained genomic patterns? By comparing disparate genomes from across different environments we may be overestimating HGT events and masking the local adaptation of microbial populations. That's enough of my rambling, let's get to the good stuff: Some interesting modes of HGT transferLet's start with phages.
Probably the most studied form of HGT is antibiotic resistance. A couple years ago, a paper from a French research group addressed the acquisition of antibiotic resistance genes mediated through phages. Specifically, this paper addressed the issue in antibiotic resistance gene detection. Inevitably, they find most detected resistance genes were overestimated ("inflated false positives") and that phages rarely encode genes related to antibiotic resistance [5]. The contrast of these first two papers is great! Phages can obviously mediate HGT but the genes being distributed are highly variable. A small shift in gears now. I want to keep discussing phages but move on to the origin of phages. So, for the next paper, we will look at the origin of single-stranded DNA viruses from traditionally exchanged plasmids in bacteria and archaea. ssDNA viruses replicate via the Rep protein of the HUH endonuclease family, a mechanism also found in plasmids. By exploring the relationships among Rep-encoding DNA viruses and transposons from plasmids, the researchers conclude that the origins of ssDNA viruses can be traced to prokaryotic plasmids [6].
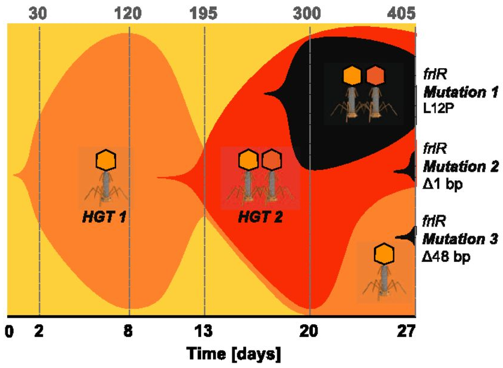
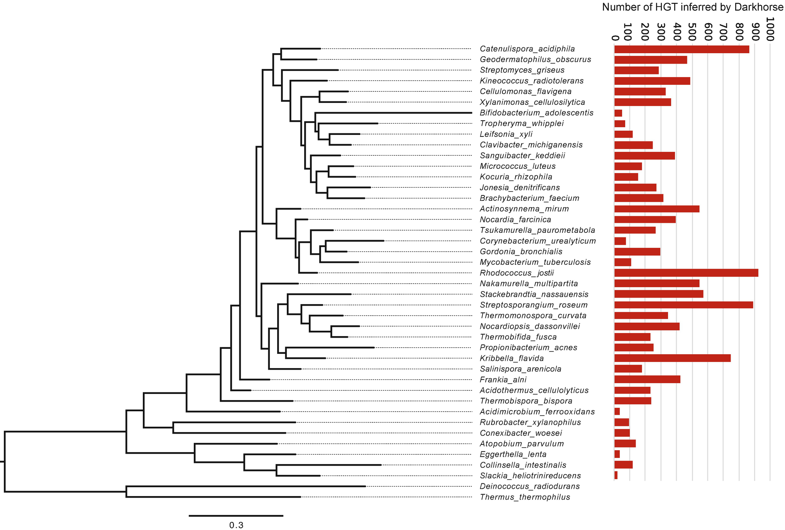
Next up, plamids! Speaking of plasmids, a recent paper documents the presence of a large megaplasmid, with the shared genetic potential to replicate, transcribe, and repair DNA as another closely-related megaplasmid [7]. Megaplasmids, themselves, are evolutionary interesting as the maintenance of these large extra-chromosomal regions possess greater evolutionary costs. The two analyzed in this study suggest strong selective pressures to maintain genetic synteny; while high divergence between orthologous groups suggest independent evolution from a common ancestral plasmid. HGT vectors such as plasmids are undergoing evolutionary processes themselves - they're not just vectors! Cross-kingdom HGTBacterial operons are unique and ubiquitous. They encode the transcription, translation, and production of proteins all in tandem. Bacteria couple these processes by clustering genes into operons, while eukaryotes spatially and temporally separate these processes. These are fundamental differences in metabolism between kingdoms. The next paper, however, found a bacterial operon being transferred, acquired, and maintained in a fungal lineage [8]. After acquisition, the operon underwent structural changes to integrate into eukaryotic synthesis - crazy! The encoded siderophore cluster maintained its high gene clustering in the fungal genome while being modified through transcription including polyadenylation. This paper highlights the boundaries of cross-domain gene transfer for the integration of a complex metabolic pathway. Detection of HGT eventsLastly, I just want to finish with some interesting reports into the frequency of HGT in bacterial systems, specifically in the Actinobacteria phyla. A recent edition on HGT included a detailed account of how HGT can shape evolution in Actinobacteria [9]. These examples include overviews of Streptomyces and Salinispora (very new and dear to me now). In both cases, the authors detail the exchange of large contiguous biosynthetic gene clusters (BGCs) and their relation to HGT, specifically a "plug-and-play" model of evolution where BGCs can be swapped in and out in concentrated genomic islands. To me, this seems extraordinary as HGT should come with (mostly) deleterious fitness costs and the integration of large genomic segments (>30kbp!!!) is hard to wrap my head around. Further, an analysis from the authors inferring HGT events in the Actinobacteria phylum is astounding (below figure), but part of me questions whether this is far overestimating HGT events. Or are we far too liberal with what we classify HGT events? For instance, a paper a couple years ago found that HGT events in Streptomyces were actually quite rare, on the order of 10 genes per million years were acquired and maintained [10]. This would make the transfer of entire BGCs almost unheard of! I would love to hear everyone else's perspective on this front. Again, I am blown away with HGT and really interested in the topic. There are tons and tons of papers I cannot even begin to break down, so let me know your thoughts!
Papers:1. Rocha EPC. (2018). Neutral Theory, microbial practice: challenges in bacterial population genetics. Molecular Biology and Evolution 35: 1338-1347.
2. Polz MF, Alm EJ, Hanage WP. (2013). Horizontal gene transfer and the evolution of bacterial and archaeal population structure. Trends in Genetics 29: 170-175. 3. Baltrus DA. (2013). Exploring the costs of horizontal gene transfer. Trends in Ecology and Evolution. 28: 489-495. 4. Frazão N, Sousa A, Lässig M, Gordo I. (2019). Horizontal gene transfer overrides mutation in Escherichia coli colonizing the mammalian gut. Proceedings to the National Academy of Sciences 116(36): 17906-17915. 5. Enault F, Briet A, Bouteille L, Roux S, Sullivan MB, Petit MA. (2017). Phages rarely encode antibiotic resistance genes: a cautionary tale for virome analyses. The ISME Journal 11: 237-247. 6. Kazlauskas D, Varsani A, Koonin EV, Krupovic M. (2019). Multiple origins of prokaryotic and eukaryotic single-stranded DNA viruses from bacterial and archaeal plasmids. Nature Communications 10:3425. 7. Smith BA, Leligdon C, Baltrus DA. (2019). Just the two of us? A family of Pseudomonas megaplasmids offers a rare glimpse into the evolution of large mobile elements. Genome Biology Evolution 11(4): 1223-1234. 8. Kominek J, Doering DT, Opulente DA, Shen XX, Zhou X, DeVirgilio J, Hulfachor AB, Groenewald M, Mcgee MA, Karlen SD, Kurtzman CP, Rokas A, Hittinger CT. (2019). Eukaryotic acquisition of a bacterial operon. Cell 176: 1356-1366. 9. Park CJ, Smith JT, Andam CP. (2019). Horizontal gene transfer and genome evolution in the phylum Actinobacteria. In: Villa T., Viñas M. (eds) Horizontal Gene Transfer. Springer, Cham 10. McDonald BR, Currie CR. (2017). Lateral gene transfer dynamics in the ancient bacterial genus Streptomyces. mBio 8: e00644-17. |
AuthorSome thoughts on some (small) things Archives
May 2023
Categories |
 RSS Feed
RSS Feed